

给吴恩达三块白板和一支马克笔,听他讲一节精彩的课。
昨天,在O’reilly举办的AI Conference上,吴恩达做了个25分钟的演讲,主题依然是“AI is the new electricity”,但内容可以说是充满诚意非常干货了。
吴恩达老师这节课,主要讲了这四部分内容:
AI能做什么?各种算法有多大商业价值?
做AI产品要注意什么?
怎样成为真正的AI公司?
给AI领导者的建议
干货摘录如下:
吴恩达的老师的开场白,依然是AI像当年的电力一样,正开始改变所有行业。
要理解AI,就要先进入我们的第一部分:
AI能做什么?
目前,AI技术做出的经济贡献几乎都来自监督学习,也就是学习从A到B,从输入到输出的映射。

比如说,输入一张照片,让机器学会判断这张照片是不是你,输出0或1。
现在最赚钱的机器学习应用,应该说是在线广告。在这个例子中,输入是广告和用户信息,输出是用户会不会点击这个广告(还是0或1)。
监督学习还可以应用在消费金融领域,输入贷款申请信息,输出用户是否会还款。
过去几年里,机器学习经历了迅速的发展,越来越擅长学习这类A到B的映射,创造了大规模的经济效益。
同时,AI的进步也体现在监督学习的输出不再限于0或1的数字。
比如说语音识别的任务,也是一种端到端的学习,输入音频,输出文本。只要有足够的数据,语音识别就能达到很好的效果。
这类算法为语音搜索、亚马逊Alexa、苹果Siri、百度DuerOS等等提供了基础。
还有输入英语输出法语的机器翻译,输入文本输出音频的TTS(Text to Speech)等等,都是监督学习的应用。
监督学习的缺点是它需要大量的标注数据,这影响了它的普及。
经常有人问我,为什么神经网络已经存在了这么多年,AI却近年来才开始快速发展?
很多人可能见过我画这张图:
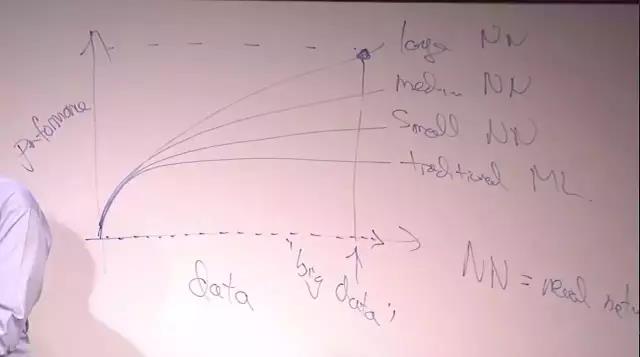
横轴是数据量,纵轴是算法的性能。
随着数据量的增加,传统机器学习算法的性能并没有明显提升,而神经网络的性能,会有比较明显的提升,神经网络越大,性能的提升就越明显。
为了达到最佳的性能,你需要两样东西:一是大量的数据,二是大型的神经网络。
还有一个问题,有很多人问我:机器学习中最大的趋势是什么?算法如何创造价值?
现在来看,创造最多价值的还是监督学习。
如果你问我监督学习之后是什么,我认为迁移学习现在也开始创造不少经济效益。可能因为这个概念不够性感,所以人们谈论得不多。
比如说你的算法从一个像ImageNet那样的大数据集学到了图像识别,然后用迁移学习,用到医学影像诊断上。
而非监督学习,我认为是非常好的长期研究项目。它也创造了一些经济价值,特别是在自然语言处理上。
强化学习也很有意思,我研究了很多年,现在也还在这方面做一些微小的工作。但是我认为,强化学习的舆论热度和经济效益有点不成比例。
强化学习对数据的饥渴程度甚至比监督学习更严重,要为强化学习算法获取到足够的数据非常难。
在打游戏这个领域,强化学习表现很好,这是因为在电子游戏中,算法可以重复玩无限次,获取无限的数据。
在机器人领域,我们也可以建立一个模拟器,相当于能让强化学习agent在其中模拟无人车、人形机器人,重复无限次“游戏”。
除了游戏和机器人领域之外,要把强化学习应用到商业和实践中还有很长的路要走。
现在,监督学习、迁移学习、非监督学习、强化学习这四类算法所创造的经济效益是递减的。
当然,这只是目前的情况。计算机学科不断有新突破,每隔几年就变个天。这四个领域中的任何一个都可能发生突破,几年内这个顺序就可能要重排。
我注意到的另一件事情是,机器学习依靠结构化数据,比非结构化数据创造了更多的经济效益。
举个结构化数据的例子,比如说你的数据库记录了用户的交易情况,谁什么时候买了什么东西,谁什么时间给谁发了信息,这就是结构化数据。
而像图像、音频、自然语言等等,就是非结构化数据。
虽然非结构化数据听起来更吸引人,舆论热度更高,但结构化数据的价值在于它通常专属于你的公司,比如说只有你的打车公司才有用户什么时候叫车、等了多长时间这样一个数据集。
所以,不要低估结构化数据结合深度学习所能创造的经济价值。
在前面谈到的几类学习算法中,单是监督学习就已经为公司、创业者创造了大量的经济价值和机会。
做AI产品要注意什么?
有一个很有意思的趋势,是AI的崛起正改变着公司间竞争的基础。
公司的壁垒不再是算法,而是数据。
当我建立一家新公司,会特地设计一个循环:

先为算法收集足够的数据,这样就能推出产品,然后通过这个产品来获取用户,用户会提供更多的数据……
有了这个循环之后,对手就很难追赶你。
这方面有一个很明显的例子:搜索公司。搜索公司有着大量的数据,显示如果用户搜了这个词,就会倾向于点哪个链接。
我很清楚该如何构建搜索算法,但是如果没有大型搜索公司那样的数据集,简直难以想象一个小团队如何构建一个同样优秀的搜索引擎。这些数据资产就是最好的壁垒。
工程师们还需要清楚这一点:
AI的范围,比监督学习广泛得多。我认为人们平时所说的AI,其实包含了好几类工具:比如机器学习、图模型、规划算法、知识表示(知识图谱)。
人们的关注点集中在机器学习和深度学习,很大程度上是因为其他工具的发展速度很平稳。
如果我现在建立一个AI团队,做AI项目,很多时候应该用图模型,有时应该用知识图谱,但是最大的机遇还是在于机器学习,这才是几年来发展最快、出现突破的领域。
接下来我要和大家分享一下我看问题的框架。
计算机,或者说算法是怎样知道该做什么的呢?它有两个知识来源,一是数据,二是人工(human engineering)。
要解决不同的问题,该用的方法也不同。
比如说在线广告,我们有那么多的数据,不需要太多的人工,深度学习算法就能学得很好。
但是在医疗领域,数据量就很少,可能只有几百个样例,这时就需要大量的人工,比如说用图模型来引入人类知识。
也有一些领域,我们有一定数量的数据,但同时也需要人工来做特征工程。

当然,还要谈一谈工程师如何学习。
很多工程师想要进入AI领域,很多人会去上在线课程,但是有一个学习途径被严重忽视了:读论文,重现其中的研究。
当你读了足够多的论文,实现了足够多的算法,它们都会内化成你的知识和想法。
要培养机器学习工程师,我推荐的流程是:上(deeplearning.ai的)机器学习课程来打基础,然后读论文并复现其中的结果,另外,还要通过参加人工智能的会议来巩固自己的基础。
怎样成为真正的AI公司?
我接下来要分享的这个观点,可能是我今天所讲的最重要的一件事。
从大约20年、25年前开始,我们开始看见互联网时代崛起,互联网成为一个重要的东西。
我从那个时代学到了一件重要的事:
商场 + 网站 ≠ 互联网公司
我认识一家大型零售公司的CIO,有一次CEO对他说:我们在网上卖东西,亚马逊也在网上卖东西,我们是一样的。
不是的。

互联网公司是如何定义的呢?不是看你有没有网站,而是看做不做A/B测试、能不能快速迭代、是否由工程师和产品经理来做决策。
这才是互联网公司的精髓。
现在我们经常听人说“AI公司”。在AI时代,我们同样要知道:
传统科技公司 + 机器学习/神经网络 ≠ AI公司(全场笑)
公司里有几个人在用神经网络,并不能让你们成为一家AI公司,要有更深层的变化。
20年前,我并不知道A/B测试对互联网公司来说有多重要。现在,我在想AI公司的核心是什么。
我认为,AI公司倾向于策略性地获取数据。我曾经用过这样一种做法:在一个地区发布产品,为了在另一个地区发布产品而获取数据,这个产品又是为了在下一个地区发布产品来获取数据用的,如此循环。而所有产品加起来,都是为了获取数据驱动一个更大的目标。
像Google和百度这样的大型AI公司,都有着非常复杂的策略,为几年后做好了准备。
第二点是比较战术性的,你可能现在就可以开始施行:AI公司通常有统一的数据仓库。
很多公司有很多数据仓库,很分散,如果工程师想把这些数据放在一起来做点什么,可能需要和50个不同的人来沟通。
所以我认为建立一个统一的数据仓库,所有的数据都存储在一起是一种很好的策略。
另外,普遍的自动化和新的职位描述也是AI公司的重要特征。
比如说在移动互联网时代,产品经理在设计交互App的时候可能会画个线框图:

然后工程师去实现它,整个流程很容易理清楚。
但是假设在AI时代,我们要做一个聊天机器人,这时候如果产品经理画个线框图说:这是头像,这是聊天气泡,并不能解决问题。
聊天气泡长什么样不重要,我需要知道的是,这个聊天机器人要说什么话。线框图对聊天机器人项目来说没什么用。

如果一个产品经理画了个无人车的线框图,说“我们要做个这个”,更是没什么用。
在AI公司里,产品经理在和工程师沟通的时候,需要学会运用数据,要求精确的反馈。
责任编辑:黄焱林




